Googlebot starts out by fetching a few web pages, and then follows the links on those webpages to find new URLs. By hopping along this path of links, the crawler is able to find new content and add it to their index called Caffeine — a massive database of discovered URLs — to later be retrieved when a searcher is seeking information that the content on that URL is a good match for.
What is a search engine index?
Search engines process and store information they find in an index, a huge database of all the content they’ve discovered and deem good enough to serve up to searchers.
Search engine ranking
When someone performs a search, search engines scour their index for highly relevant content and then orders that content in the hopes of solving the searcher’s query. This ordering of search results by relevance is known as ranking. In general, you can assume that the higher a website is ranked, the more relevant the search engine believes that site is to the query.
It’s possible to block search engine crawlers from part or all of your site, or instruct search engines to avoid storing certain pages in their index. While there can be reasons for doing this, if you want your content found by searchers, you have to first make sure it’s accessible to crawlers and is indexable. Otherwise, it’s as good as invisible.
By the end of this chapter, you’ll have the context you need to work with the search engine, rather than against it!
Crawling: Can search engines find your pages?
As you’ve just learned, making sure your site gets crawled and indexed is a prerequisite to showing up in the SERPs. If you already have a website, it might be a good idea to start off by seeing how many of your pages are in the index. This will yield some great insights into whether Google is crawling and finding all the pages you want it to, and none that you don’t.
One way to check your indexed pages is “site:yourdomain.com”, an advanced search operator. Head to Google and type “site:yourdomain.com” into the search bar. This will return results Google has in its index for the site specified:
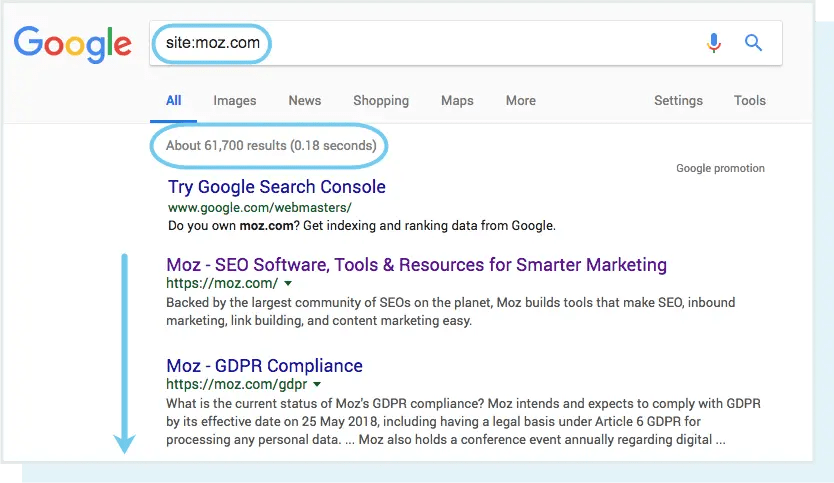
The number of results Google displays (see “About XX results” above) isn’t exact, but it does give you a solid idea of which pages are indexed on your site and how they are currently showing up in search results.
For more accurate results, monitor and use the Index Coverage report in Google Search Console. You can sign up for a free Google Search Console account if you don’t currently have one. With this tool, you can submit sitemaps for your site and monitor how many submitted pages have actually been added to Google’s index, among other things.
If you’re not showing up anywhere in the search results, there are a few possible reasons why:
- Your site is brand new and hasn’t been crawled yet.
- Your site isn’t linked to from any external websites.
- Your site’s navigation makes it hard for a robot to crawl it effectively.
- Your site contains some basic code called crawler directives that is blocking search engines.
- Your site has been penalized by Google for spammy tactics.
Tell search engines how to crawl your site
If you used Google Search Console or the “site:domain.com” advanced search operator and found that some of your important pages are missing from the index and/or some of your unimportant pages have been mistakenly indexed, there are some optimizations you can implement to better direct Googlebot how you want your web content crawled. Telling search engines how to crawl your site can give you better control of what ends up in the index.
Most people think about making sure Google can find their important pages, but it’s easy to forget that there are likely pages you don’t want Googlebot to find. These might include things like old URLs that have thin content, duplicate URLs (such as sort-and-filter parameters for e-commerce), special promo code pages, staging or test pages, and so on.
To direct Googlebot away from certain pages and sections of your site, use robots.txt.
Robots.txt
Robots.txt files are located in the root directory of websites (ex. yourdomain.com/robots.txt) and suggest which parts of your site search engines should and shouldn’t crawl, as well as the speed at which they crawl your site, via specific robots.txt directives.
How Googlebot treats robots.txt files
- If Googlebot can’t find a robots.txt file for a site, it proceeds to crawl the site.
- If Googlebot finds a robots.txt file for a site, it will usually abide by the suggestions and proceed to crawl the site.
- If Googlebot encounters an error while trying to access a site’s robots.txt file and can’t determine if one exists or not, it won’t crawl the site.
Not all web robots follow robots.txt. People with bad intentions (e.g., e-mail address scrapers) build bots that don’t follow this protocol. In fact, some bad actors use robots.txt files to find where you’ve located your private content. Although it might seem logical to block crawlers from private pages such as login and administration pages so that they don’t show up in the index, placing the location of those URLs in a publicly accessible robots.txt file also means that people with malicious intent can more easily find them. It’s better to NoIndex these pages and gate them behind a login form rather than place them in your robots.txt file.
You can read more details about this in the robots.txt portion of our Learning Center.
Defining URL parameters in GSC
Some sites (most common with e-commerce) make the same content available on multiple different URLs by appending certain parameters to URLs. If you’ve ever shopped online, you’ve likely narrowed down your search via filters. For example, you may search for “shoes” on Amazon, and then refine your search by size, color, and style. Each time you refine, the URL changes slightly:
https://www.example.com/products/women/dresses/green.htmhttps://www.example.com/products/women?category=dresses&color=greenhttps://example.com/shopindex.php?product_id=32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
How does Google know which version of the URL to serve to searchers? Google does a pretty good job at figuring out the representative URL on its own, but you can use the URL Parameters feature in Google Search Console to tell Google exactly how you want them to treat your pages. If you use this feature to tell Googlebot “crawl no URLs with ____ parameter,” then you’re essentially asking to hide this content from Googlebot, which could result in the removal of those pages from search results. That’s what you want if those parameters create duplicate pages, but not ideal if you want those pages to be indexed.
Can crawlers find all your important content?
Now that you know some tactics for ensuring search engine crawlers stay away from your unimportant content, let’s learn about the optimizations that can help Googlebot find your important pages.
Sometimes a search engine will be able to find parts of your site by crawling, but other pages or sections might be obscured for one reason or another. It’s important to make sure that search engines are able to discover all the content you want indexed, and not just your homepage.
Ask yourself this: Can the bot crawl through your website, and not just to it?

Is your content hidden behind login forms?
If you require users to log in, fill out forms, or answer surveys before accessing certain content, search engines won’t see those protected pages. A crawler is definitely not going to log in.
Are you relying on search forms?
Robots cannot use search forms. Some individuals believe that if they place a search box on their site, search engines will be able to find everything that their visitors search for.
Is text hidden within non-text content?
Non-text media forms (images, video, GIFs, etc.) should not be used to display text that you wish to be indexed. While search engines are getting better at recognizing images, there’s no guarantee they will be able to read and understand it just yet. It’s always best to add text within the <HTML> markup of your webpage.
Can search engines follow your site navigation?
Just as a crawler needs to discover your site via links from other sites, it needs a path of links on your own site to guide it from page to page. If you’ve got a page you want search engines to find but it isn’t linked to from any other pages, it’s as good as invisible. Many sites make the critical mistake of structuring their navigation in ways that are inaccessible to search engines, hindering their ability to get listed in search results.

5xx Codes: When search engine crawlers can’t access your content due to a server error
5xx errors are server errors, meaning the server the web page is located on failed to fulfill the searcher or search engine’s request to access the page. In Google Search Console’s “Crawl Error” report, there is a tab dedicated to these errors. These typically happen because the request for the URL timed out, so Googlebot abandoned the request. View Google’s documentation to learn more about fixing server connectivity issues.
Thankfully, there is a way to tell both searchers and search engines that your page has moved — the 301 (permanent) redirect.

Indexing: How do search engines interpret and store your pages?
Once you’ve ensured your site has been crawled, the next order of business is to make sure it can be indexed. That’s right — just because your site can be discovered and crawled by a search engine doesn’t necessarily mean that it will be stored in their index. In the previous section on crawling, we discussed how search engines discover your web pages. The index is where your discovered pages are stored. After a crawler finds a page, the search engine renders it just like a browser would. In the process of doing so, the search engine analyzes that page’s contents. All of that information is stored in its index.

Can I see how a Googlebot crawler sees my pages?
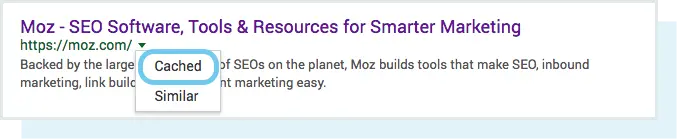
Yes, the cached version of your page will reflect a snapshot of the last time Googlebot crawled it.
Google crawls and caches web pages at different frequencies. More established, well-known sites that post frequently like https://www.nytimes.com will be crawled more frequently than the much-less-famous website for Roger the Mozbot’s side hustle, http://www.rogerlovescupcakes…. (if only it were real…)
You can view what your cached version of a page looks like by clicking the drop-down arrow next to the URL in the SERP and choosing “Cached”:
Ranking: How do search engines rank URLs?
How do search engines ensure that when someone types a query into the search bar, they get relevant results in return? That process is known as ranking, or the ordering of search results by most relevant to least relevant to a particular query.

The role links play in SEO
When we talk about links, we could mean two things. Backlinks or “inbound links” are links from other websites that point to your website, while internal links are links on your own site that point to your other pages (on the same site).

Links have historically played a big role in SEO. Very early on, search engines needed help figuring out which URLs were more trustworthy than others to help them determine how to rank search results. Calculating the number of links pointing to any given site helped them do this.
Backlinks work very similarly to real-life WoM (Word-of-Mouth) referrals. Let’s take a hypothetical coffee shop, Jenny’s Coffee, as an example:
- Referrals from others = good sign of authority
- Example: Many different people have all told you that Jenny’s Coffee is the best in town
- Referrals from yourself = biased, so not a good sign of authority
- Example: Jenny claims that Jenny’s Coffee is the best in town
- Referrals from irrelevant or low-quality sources = not a good sign of authority and could even get you flagged for spam
- Example: Jenny paid to have people who have never visited her coffee shop tell others how good it is.
- No referrals = unclear authority
- Example: Jenny’s Coffee might be good, but you’ve been unable to find anyone who has an opinion so you can’t be sure.
This is why PageRank was created. PageRank (part of Google’s core algorithm) is a link analysis algorithm named after one of Google’s founders, Larry Page. PageRank estimates the importance of a web page by measuring the quality and quantity of links pointing to it. The assumption is that the more relevant, important, and trustworthy a web page is, the more links it will have earned.
The more natural backlinks you have from high-authority (trusted) websites, the better your odds are to rank higher within search results.
What is RankBrain?
RankBrain is the machine learning component of Google’s core algorithm. Machine learning is a computer program that continues to improve its predictions over time through new observations and training data. In other words, it’s always learning, and because it’s always learning, search results should be constantly improving.
For example, if RankBrain notices a lower ranking URL providing a better result to users than the higher ranking URLs, you can bet that RankBrain will adjust those results, moving the more relevant result higher and demoting the lesser relevant pages as a byproduct.
The evolution of search results
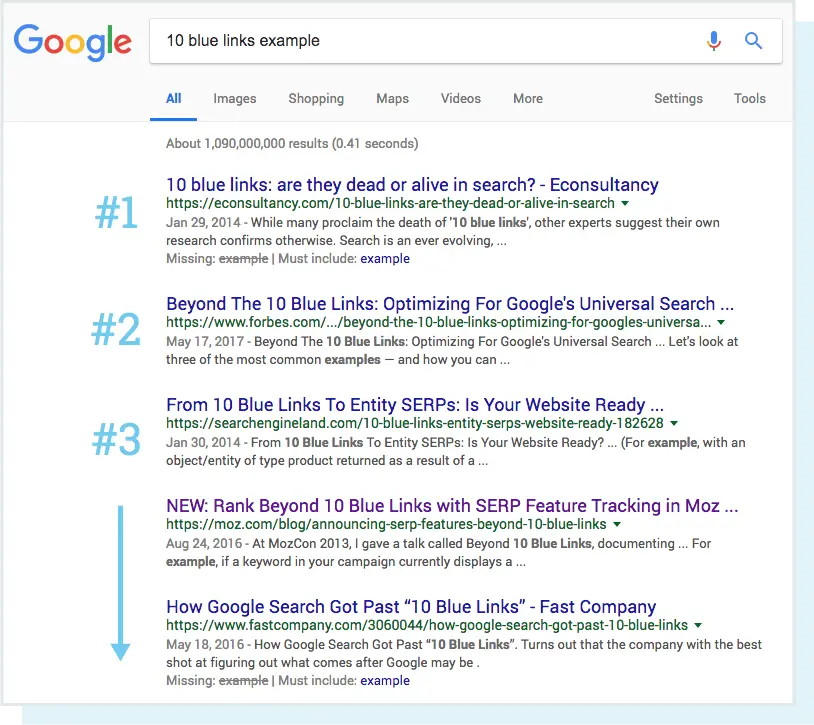
Back when search engines lacked a lot of the sophistication they have today, the term “10 blue links” was coined to describe the flat structure of the SERP. Any time a search was performed, Google would return a page with 10 organic results, each in the same format.
[Bonus!] Local engagement
Although not listed by Google as a local ranking factor, the role of engagement is only going to increase as time goes on. Google continues to enrich local results by incorporating real-world data like popular times to visit and average length of visits…